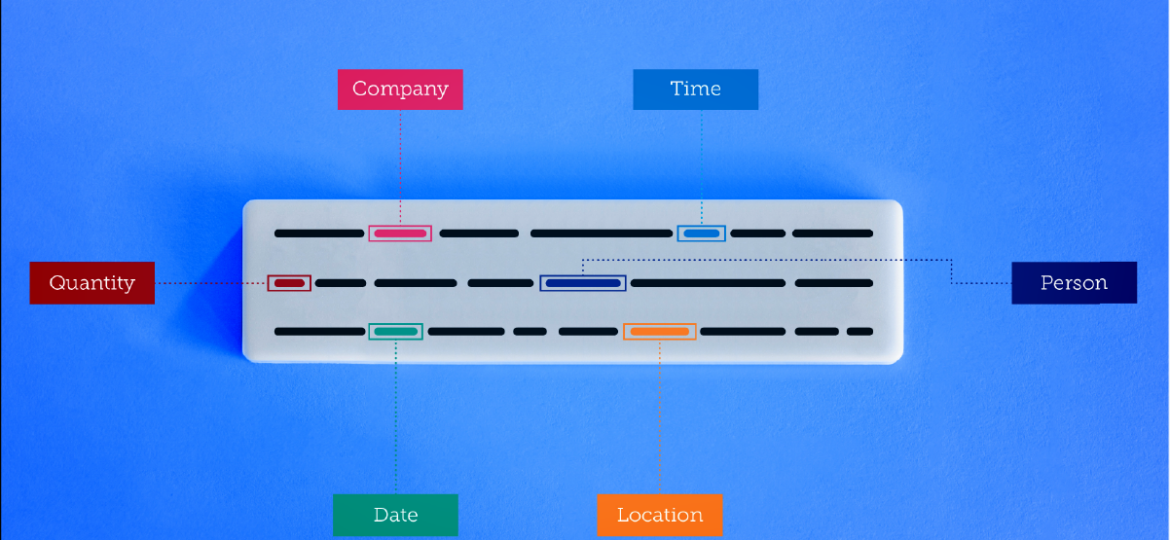
Comparing the Effectiveness of Entity Extraction between NLP and LLMs
Search

We describe the process of using retrieval-augmented generation (RAG) to create a question-answering system about Solr and OpenSearch using an assortment of LLMs from HuggingFace and OpenAI.

In Lucene-based search engines like OpenSearch and Solr, keyword aggregations ignore duplicate values that occur within a multi-valued field. We built an OpenSearch plugin to overcome this limitation.

We created a POC vector search application using OpenSearch. In this post, we discuss what we did to get it working as well as investigate how popular search features like sorting, aggregating and filtering can be utilized in vector search.

When it comes to analyzing Solr logs, Solr does have some out of the box tools. However, we’ve found that those tools don’t give a lot of options for creating rich visual analysis, and don’t offer a way to analyze logs in real time. So what do we do? We turn to another open-source platform: Elastic.

New in Solr 9.2! We created a way for the Query Elevation Component to exclude filters. Read about how we did this and what you should know about this new feature.

Learn about our most popular service, where we take a deep dive into what may not be working for your Solr, Elasticsearch, or OpenSearch instance.

Open-source search engines are constantly being updated to add features, improve existing features, and fix vulnerabilities. Here are some more reasons you would want to update accordingly and how we can help.

New in Solr & Lucene 9 is the ability to do inequality operations to search against payloads on terms. We’ll go through this how new feature works using some different use cases.

The KMW team’s contribution to Solr 8.6 is a new Cross Collection Join query method, enabling Solr to support a multi-sharded distributed query for the first time. We’ll tell you all about how it works.