
Open-source search engines are constantly being updated to add features, improve existing features, and fix vulnerabilities. Here are some more reasons you would want to update accordingly and how we can help.

New in Solr & Lucene 9 is the ability to do inequality operations to search against payloads on terms. We’ll go through this how new feature works using some different use cases.

The KMW team’s contribution to Solr 8.6 is a new Cross Collection Join query method, enabling Solr to support a multi-sharded distributed query for the first time. We’ll tell you all about how it works.

We go over how we extended Solr’s JSON Facet API to return large amounts of data and reports for a client’s use case.
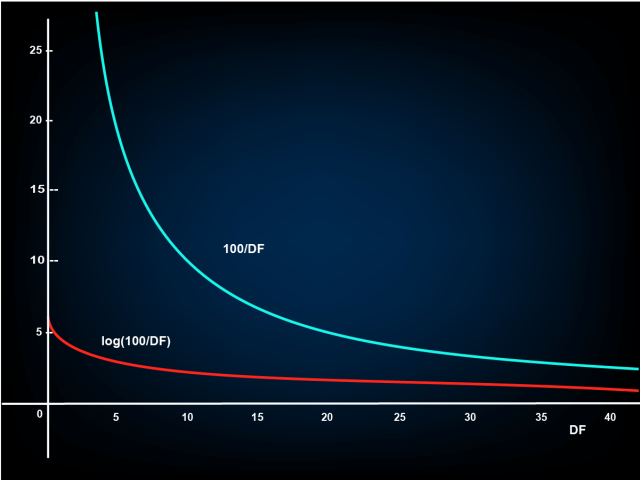
This post will show you precisely how BM25 builds upon TF-IDF, what its parameters do, and why it is so effective.

KMW hosted the Boston Elasticsearch meetup group, and our own Rudi Seitz gave an in-depth talk about how relevancy works in a search engine. In this post learn about when he covered, including: how scoring is computed, query structure and analysis chains, and approaches to tuning relevancy.

Instead of delving into the mathematical definitions of TF-IDF and BM25, we will help you develop an intuitive understanding of these metrics using a series of simple examples.
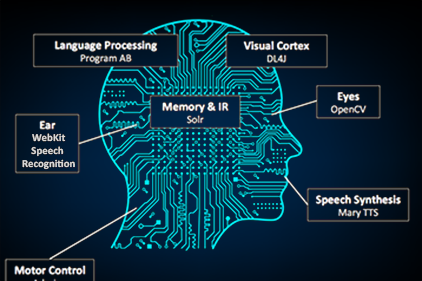
KMW Founder, Kevin Watters, gives a talk at the Activate Search & AI conference on using Search as the brain for an open sourced, life-sized, 3D printed, humanoid robot. Of particular interest to the Solr community was the section of this talk highlighting training a Neural Network off of a Solr index in real-time.

Customer issues addressed by a KMW Solr Audit Include:
-Cluster instability
-Query throughput and latency issues
-Relevancy issues / poor recall or precision
-Ingestion / index latency concerns
-Planning for a Solr upgrade or major platform update
-Problematic Hardware/cluster sizing and/or scaling issues
-Defunct operational practices