
Search & AI Engineer at KMW Technology
Entities are really important for search, but what’s the best way to do it?
The ability to analyze a piece of text and identify the key entities within it can have lots of practical search uses like improving search relevancy; enabling faceting and filtering classifying documents and even obfuscation of sensitive data.
As a natural language problem, entity extraction is not new but it’s always been tricky to do well. There are lots of traditional NLP models for entity extraction and recently LLMs have shown promising abilities too. For search applications we are typically trying to balance excellent entity extraction along with operational needs like running fast and not consuming too many resources. So what is the best way to do entity extraction for modern search applications?
In this blog post we are going to compare traditional NLP models with LLMs to see how they measure up. We’ll focus on extracting the names of people, organizations, or locations within a body of text. We’ll discuss ways entity extraction can improve the search experience, analyze the performance of traditional models and large language models, run a few experiments, and conclude with a review of our findings
A Simple Example
Imagine we have four documents we want to index:
{
“id”: 1
“text”: “Will, are you going to the store today?”
}
{
“id”: 2
“text”: “Will you go to the store today?”
}
{
“id”: 3
“text”: “I hope you will join us.”
}
{
“id”: 4
“text”: “Is Hope going to be joining us?”
}
Let’s say you want to search for documents referencing a certain person. In some cases, you might get away with just searching for their name, as-is, in text. But, when you search for names like Will or Hope, your search engine will likely return documents that use these words in a different context. As you can see, “will” is found in documents 1, 2, and 3, but only document 1 actually references someone named Will. We run into a similar issue when searching for “hope” as well.
Having some irrelevant documents returned is, of course, not ideal. But in practice, the problem may be more than just a minor nuisance. Terms like Will and Hope could be used more often as English words rather than names. Documents that naturally use the word “will” multiple times might score higher than documents mentioning a person named Will. Making matters even worse, the text might reference Will with pronouns instead of stating his name repeatedly, further decreasing the document’s search score.
So… just running a search on “text” won’t always suffice. To avoid manually pruning through your search results to remove the irrelevant documents, you’ll want to enrich your content before indexing.
With entity extraction, we can enrich our documents like so:
{
“id”: 1
“text”: “Will, are you going to the store today?”
“people”: [“Will”]
}
{
“id”: 2
“text”: “Will you go to the store today?”
}
{
“id”: 3
“text”: “I hope you will join us.”
}
{
“id”: 4
“text”: “Is Hope going to be joining us?”
“people”: [“Hope”]
}
If we extract entities from the text, we can attach lists of names mentioned to the document. Now, if we want to search for documents that reference somebody named Will, we would search on “people” instead of “text”. This allows us to ensure documents like 2 and 3 don’t hinder our search process or contaminate our results. This is definitely a simple use case – different use cases will certainly have unique challenges to overcome.
Our Entity Extraction Approach
There exist many statistical/rules-based models for entity extraction and named entity recognition. For our testing, we used Apache OpenNLP’s pretrained models and Stanford CoreNLP’s built-in named entity recognition models. But they aren’t perfect, and with the ever increasing popularity of large language models (LLMs), we thought it would be interesting to see how an LLM performs entity extraction compared against these legacy approaches.
We theorized that an LLM had the potential to extract certain names that more traditional models may be likely to miss. (In particular, we figured an LLM would be more likely to extract a “newer” name that was uncommon when the traditional models were trained.) But, we also believed an LLM could potentially get “distracted” and underperform the traditional models on longer pieces of text.
In order to test our theories, we ran four different experiments:
- Baseline: We started by evaluating the performance of OpenNLP, CoreNLP, and Google’s gemma3, a popular and capable open-source LLM. The default version of the model is about 3 GB in size and has roughly 4 billion parameters, making it suitable for use on modern hardware. For each model, we evaluated its precision, recall, and F1 score.
- Number of Parameters: We introduced two new variants of gemma3 with a different number of parameters. We discussed how using more / less parameters appeared to affect the results.
- Two Pass: Using the two strongest models – CoreNLP and gemma3 – we instructed gemma3 to observe and edit the output of CoreNLP as it saw fit.
- Alternate Model: We evaluated another popular model, deepseek-r1, against OpenNLP and CoreNLP, to see if there were any notable differences.
For all experiments, we used a publicly available and fully annotated wikigold dataset, allowing us to evaluate the models against a source of truth. Across the 140+ wiki articles, there were roughly 3,000 words annotated as a person, organization, or location.
As part of our evaluation, we worked with Lucille, our open-source Search ETL solution that allowed us to pass text through entity extraction processes and update each document with the output. We created a custom Connector to process the wikigold dataset into Lucille, including the article’s text as well as lists of the annotated (or “gold”) people, organization, and location names.
To perform entity extraction, we used three different Lucille Stages. We created a custom Stage to extract people, organization, and location names using OpenNLP. We did the same for CoreNLP as well. To work with an LLM, we used Lucille’s PromptOllama Stage, which allows you to provide parts (or all) of a document to a compatible LLM for generic enrichment. The model was instructed to read the source text and output a JSON object including the names of people, organizations, and locations mentioned in the document. Lucille then integrated the model’s JSON response into the document. The models did not have access to the output of other Stages – they only saw the source text.
Here’s an example of what a finalized document looked like, after we normalized the output for evaluation:
{
“text”: “010 is the tenth album from Japanese Punk Techno band The Mad Capsule Markets . This album proved to be more commercial and more techno-based than Osc-Dis , with heavily synthesized songs like Introduction 010 and Come . Founding member Kojima Minoru played guitar on Good Day , and Wardanceis cover of a song by UK post punk industrial band Killing Joke . XXX can of This had a different meaning , and most people did n't understand what the song was about . it was later explained that the song was about Cannabis ( ' can of this ' sounding like Cannabis when said faster ) it is uncertain if they were told to change the lyric like they did on P.O.P and HUMANITY . UK Edition came with the OSC-DIS video , and most of the tracks were re-engineered .”
“openNLP_people”: []
“coreNLP_people”: [“kojima”, “minoru”]
“ollama_people”: []
“gold_people”: [“kojima”, “minoru”]
“openNLP_organizations”: [“uk”, “killing”, “joke”, “founding”]
“coreNLP_organizations”: []
“ollama_organizations”: [“the”, “mad”, “capsule”, “markets”, “meta”, “killing”, “joke”]
“gold_organizations”: [“the”, “killing”, “mad”, “markets”, “capsule”, “joke”]
“openNLP_locations”: []
“coreNLP_locations”: [“uk”]
“ollama_locations”: [“uk”]
“gold_locations”: [“uk”]
}
For the purposes of evaluation, we did not index the documents into a search engine. Instead, they were indexed into a CSV, which stored the original text, annotated entities, and output from each model. We then ran a custom script to analyze the models’ performance. Using the annotated people, organizations, and locations from the wikigold dataset, we were able to compute some key metrics for each model:
- Precision – What percentage of the person/organization/location names output by a model were annotated as such in the dataset?
- Recall – What percentage of the annotated person/organization/location names in the dataset were output by the model?
- F1 – The “harmonic mean” of precision and recall. Considered a solid overall indicator of a model’s performance.
- Unique Gold Words – How many gold names did a model mention that no other model did?
ExperIminets & Results
Experiment 1: Number of Parameters
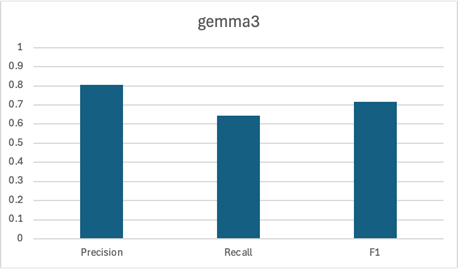
We began by creating a pipeline that used three different models: OpenNLP, CoreNLP, and gemma3. Each model ran independently of the other, meaning they were not aware of each other’s output. Here are the precision, recall, and F1 scores for each model:
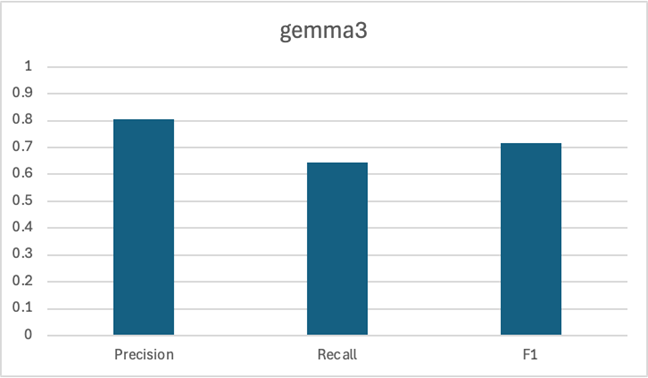
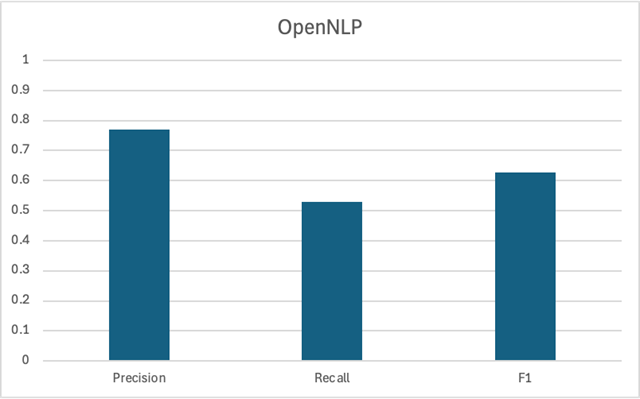
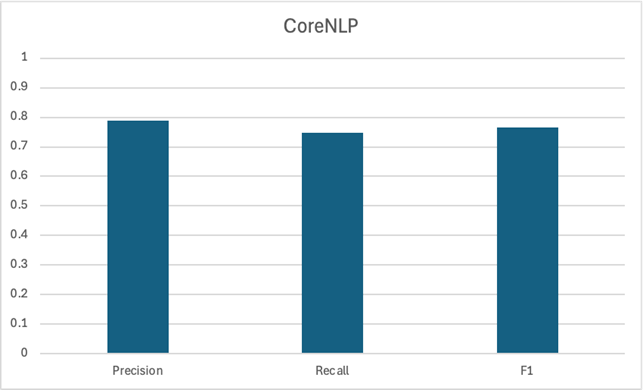
Clearly, CoreNLP is the strongest contender here, with gemma3 in a close second. Both had similar F1 scores of about ~0.75. OpenNLP wasn’t the strongest contender with a lower F1 score. We should also consider the latency associated with running the LLM.
On average, gemma3 took about 8 seconds to respond per Document, slowing the pipeline down substantially. (The experiment was run on an Apple M1 Pro with 16 GB of RAM.)
We also analyzed the effect of text length on model performance. Here, we considered just the top performing models – CoreNLP and gemma3. We calculated the same metrics (precision, recall, F1) for each wiki article. There were a few articles with 900+ words that we excluded to avoid skewing the results. We also excluded articles with less than 100 words. Since these documents were very short, they usually just didn’t reference names of a certain type. As a result, the model scores were primarily either zero or one, which made the results very volatile and difficult to observe:
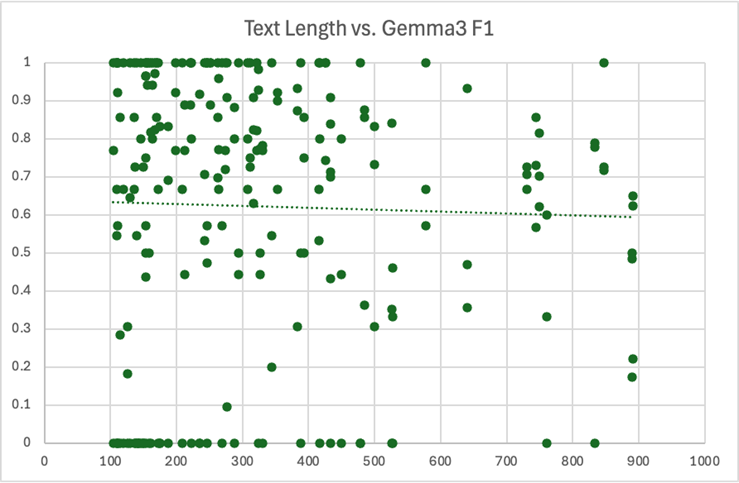
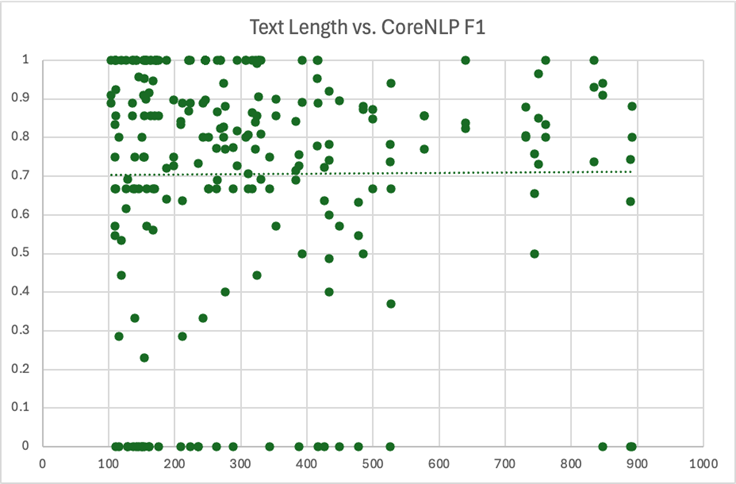
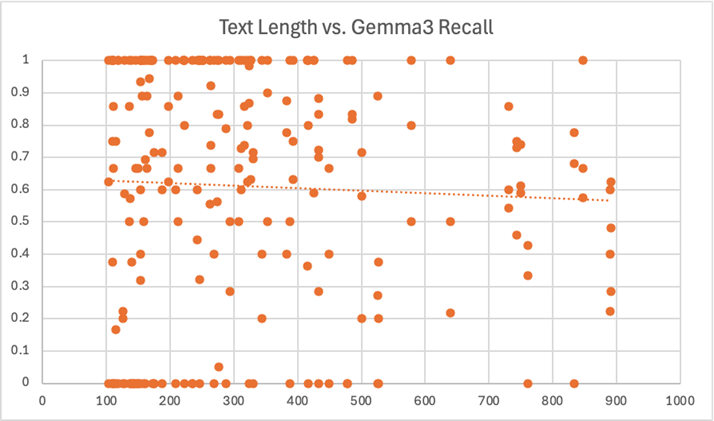
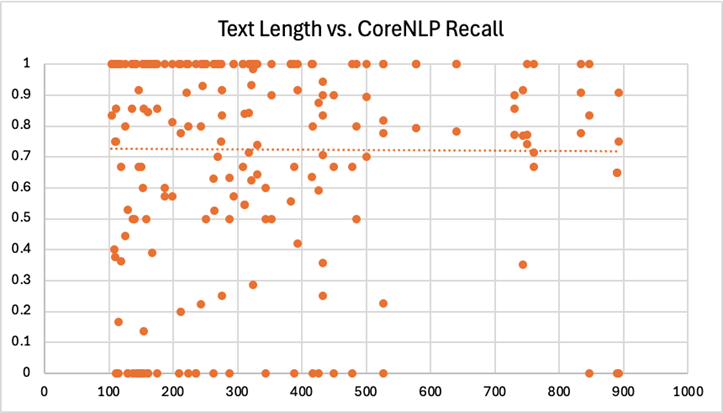
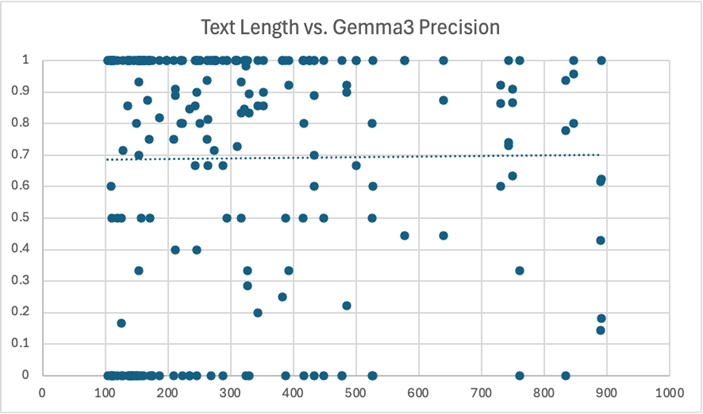
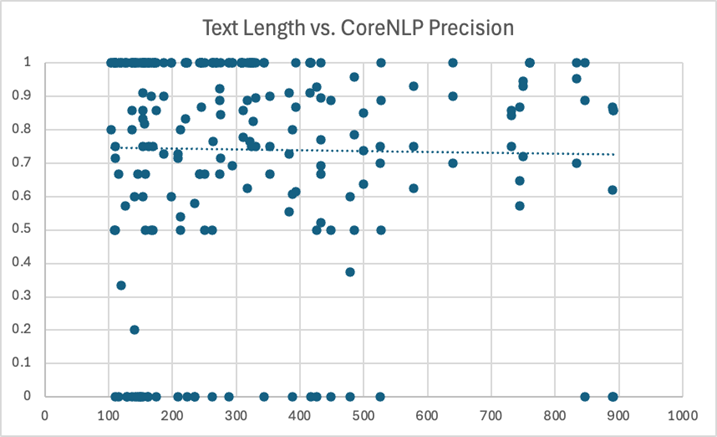
As expected, the data here was a bit scattered. Since many points overlapped at the top and bottom of each chart, we did include lines of best fit to help visualize the overall trend. However, these lines should be interpreted cautiously, as they all had a very low R-squared value. In other words, the length of a piece of text shouldn’t be used to singularly predict the recall, precision, or F1 score you’ll get from a model.
Again, these charts should be observed with caution, as there were a multitude of factors at play here. But, it does seem reasonable to suggest that there was some sort of relationship between longer text and LLM underperformance. CoreNLP, on the other hand, appears to have been remarkably consistent.
Experiment 2: Number of Parameters
Our next pipeline included five different models (OpenNLP, CoreNLP, and three variants of gemma3). In addition to the previous pipeline’s models, we added a smaller variant of gemma3, gemma3:1b, and a larger variant of gemma3, gemma3:12b. As we mentioned above, gemma3, had 4 billion parameters and was a little more than 3 GB in size. The smaller variant, gemma3:1b, had 1 billion parameters and was less than 1 GB in size. The larger variant, gemma3:12b, had 12 billion parameters and was about 8 GB in size.
Here are the results we found:
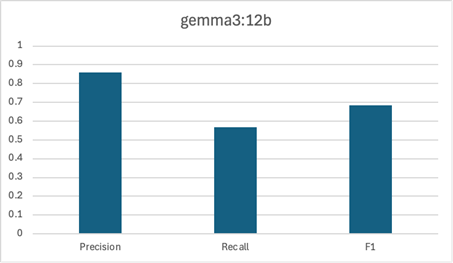
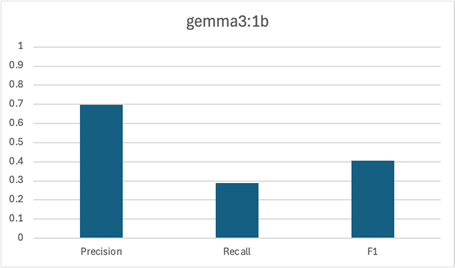
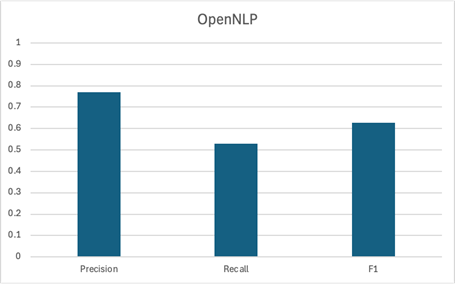
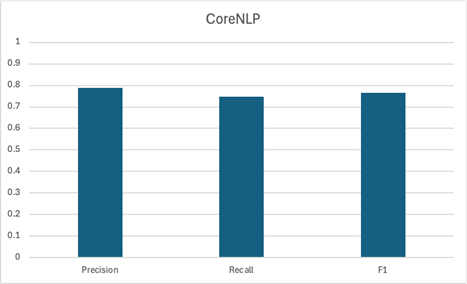
Again, gemma3 and CoreNLP are the strongest contenders here. The smallest LLM, gemma3:1b, didn’t do well – not only did it have a poor F1 score, but we found it was actually struggling to follow our instructions. Surprisingly, the largest LLM, gemma3:12b, was actually a bit worse than the medium variant, gemma3. Compared to gemma3, gemma3:12b had a somewhat higher precision but a notably lower recall. It seems that this larger model was a bit too cautious when engaging with the source text.
For this experiment, we also calculated the number of “gold” words that were uniquely mentioned by each model.
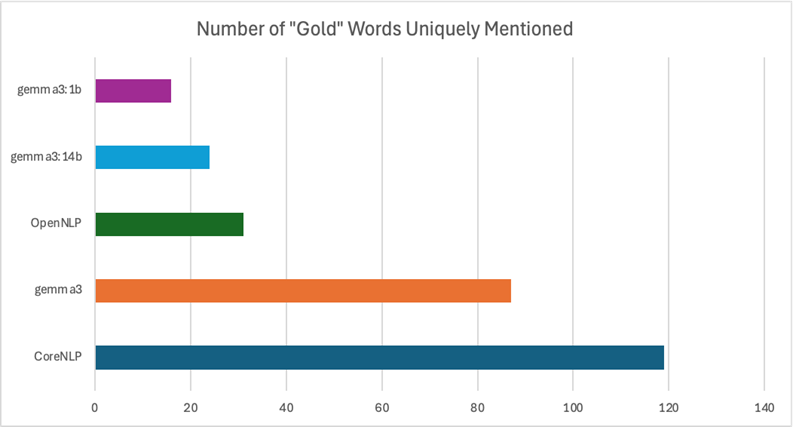
As expected, CoreNLP and gemma3 pick up on the most unique gold words. Interestingly, the small and large gemma variants had the fewest unique gold words – even less than OpenNLP.
Experiment 3: Two Pass
In the previous experiment, we saw that gemma3 listed ~85 “gold” words that no other model did. CoreNLP uniquely listed ~115 “gold” words. We wondered if a better overall result could be achieved by having the two models actually work together to improve their output. Ideally, an LLM could catch some of these “additional” names (increasing recall) and make some minor changes to CoreNLP’s output (increasing precision).
(LLM Request)
{
“text”: “The 38th NAACP Image Awards televised live on FOX in Hollywood, California, hosted by LL Cool J.”
“organizations”: [“FOX in”],
“locations”: [“Hollywood, California”]
}
(LLM Response)
{
“people”: [“LL Cool J”]
“organizations”: [“FOX”, “NAACP”],
“locations”: [“Hollywood, California”]
}
Our modified Lucille ETL pipeline used only two models. First, CoreNLP extracted entity names, as usual. Then, we used gemma3 again, but with a new system prompt and a different PromptOllama configuration. Now, gemma3 was instructed to “edit” the results from CoreNLP as needed. The stage’s configuration ensured the request included the source text and the people, organization, and location names extracted by CoreNLP. (This was the only pipeline where an LLM was provided results from a previous model.) Together, the models had the following scores:
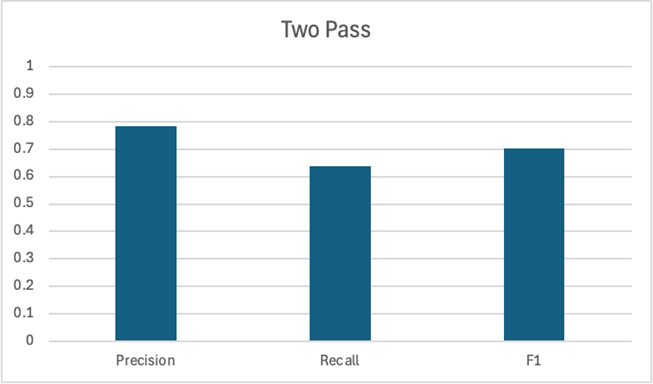
Unfortunately, this approach was actually less performant, with an F1 score lower than CoreNLP or gemma3 operating individually. Instead of finding a way to include those “unique” gold words, it looks like the LLM had an inclination to delete the names output by CoreNLP. (In a later chart, you’ll see the total number of words output in this “two pass” pipeline is very similar to the number output by gemma3 alone.) While there are certainly a variety of ways to tweak the pipeline, it seemed we weren’t going to obtain the results we were looking for with this approach.
Experiment 4: Alternate Model
Lastly, we wanted to measure the performance of an alternate LLM. We created a pipeline similar to the first experiment, but PromptOllama used deepseek-r1 instead of gemma3. deepseek-r1 is a “reasoning” model, which could potentially yield different results. The variant we used, deepseek-r1:14b, had 14 billion parameters, and was roughly 9 GB in size. This made it slightly larger than gemma3:12b, the “large” model used in the first pipeline.
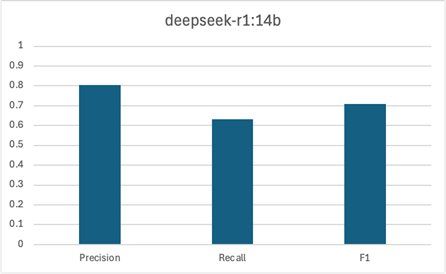
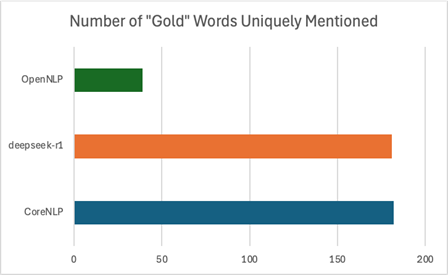
The “unique” count only considered these three models, so the results aren’t directly comparable to the same chart from Experiment 2.
We can see that deepseek-r1’s performance was roughly in line with gemma3’s performance from earlier, with an F1 score of roughly 0.7.
Again, we noticed that CoreNLP and the LLM were each picking up on many gold words that the other models weren’t. We still wanted to find a way to capture as many gold words as possible. So, instead of running another pipeline, we decided to just calculate the scores associated with combining the outputs of every model:
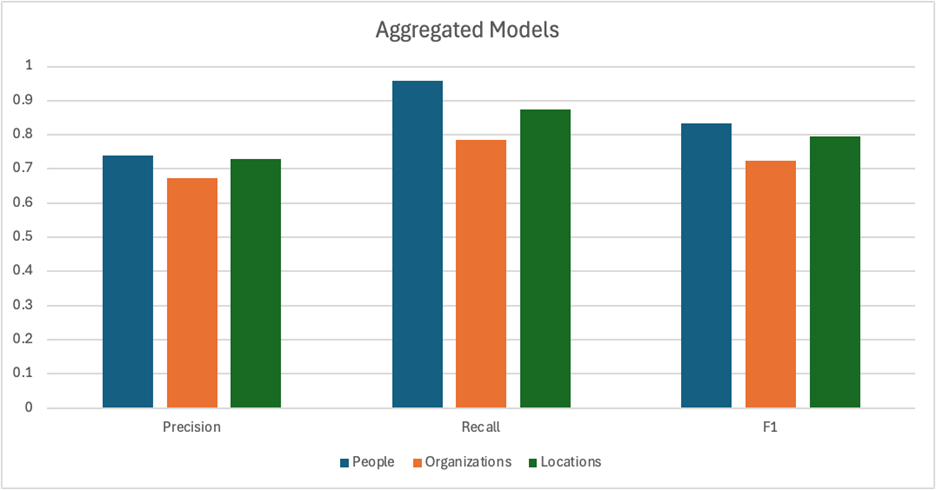
As you could imagine, we got higher recall at the cost of reduced precision. We picked up on more of the gold words, but less of the words listed were actually gold words from the original dataset. Interestingly, the F1 score remained roughly the same, despite pronounced shifts in precision and recall.
If you’re looking to run enhanced searches on your documents, a higher recall will help ensure you don’t miss out on any names. But, if you’re looking to run aggregations or facets on the extracted entities, these extra non-gold entries could undermine the quality of your insights.
Again, we noticed that CoreNLP and the LLM were each picking up on many gold words that the other models weren’t. We still wanted to find a way to capture as many gold words as possible. So, instead of running another pipeline, we decided to just calculate the scores associated with combining the outputs of every model:
Pulling The Data Together
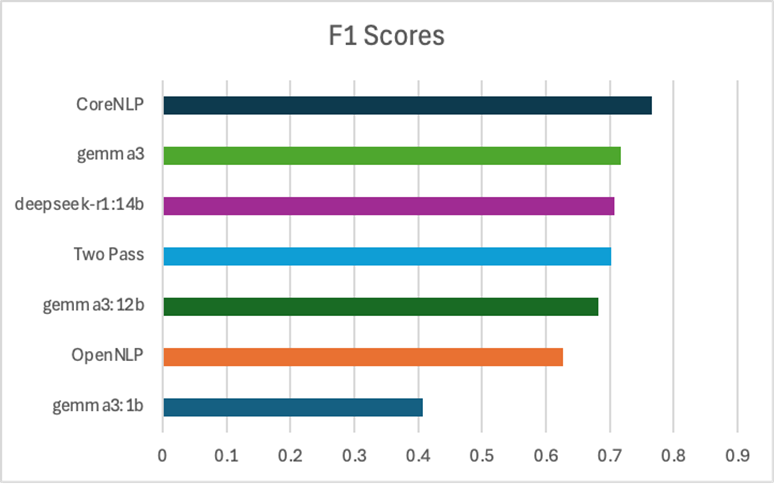
Lastly, here are some higher level results comparing all of the models.
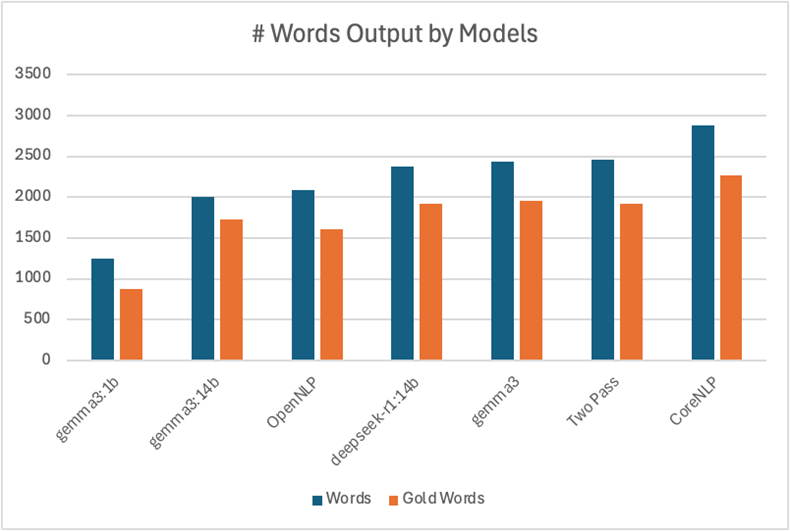
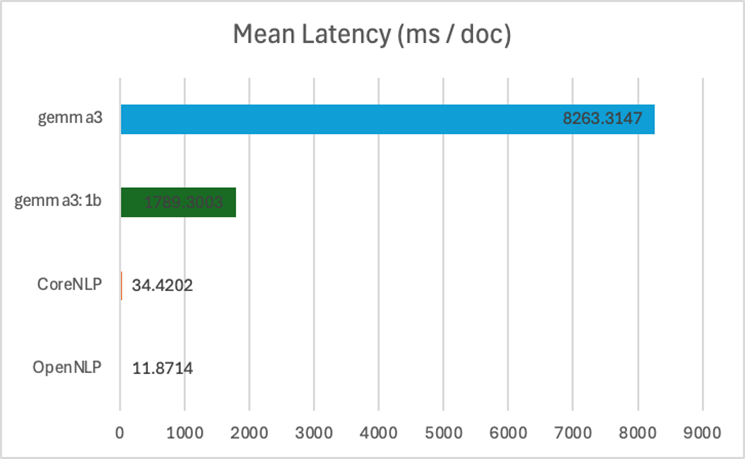
Conclusion
Overall, it looks like traditional NLP models are still valuable, even as LLMs are frequently touted as the solution to all of life’s problems. CoreNLP generally led the way with the highest F1 scores and only a fraction of the LLMs’ high latency. But some of the LLMs we tested were still very strong alternatives. They had high F1 scores and picked up on some words that CoreNLP didn’t. OpenNLP did underperform, but we were using its pretrained models. Training a custom model with OpenNLP’s architecture could yield improved results.
Though CoreNLP outperformed, LLMs could still play a vital role in many entity extraction solutions, as they are extremely versatile and require minimal setup. If you don’t have the time to find a training dataset, cleanse it, and then train and evaluate a model, an LLM is certainly a viable option. Additionally, an LLM could handle data in a variety of languages without any additional configuration or training needed. If our data was in multiple languages, we would have had to completely overhaul our pipeline to support this data.
As such, any entity extraction solution you build should be tailored to your use case. While you can’t really go wrong with a traditional model, you may want to consider integrating an LLM into your process. Are your documents in multiple languages? Do they have very long pieces of text? How many documents do you have? How much compute is available to you? You’ll have to take a holistic approach to designing your solution.
Based on our findings, even in a world filled with LLMs, it looks like traditional models still have a place in addressing classic NLP problems.
May 20, 2025

June 23, 2024

May 30, 2024

March 29, 2023

December 17, 2022

November 17, 2022

September 30, 2022

July 2, 2022