
Search Engineer at KMW Technology
What We’ve Accomplished
With the recent advances in Large Language Models (LLMs), a very natural intersection with traditional Search has arisen. Historically, the only way to “ask” a search engine a question is to provide some search keywords and the system responds with a set of ordered documents which hopefully contain an answer. In a RAG system however, you ask your question in natural language, it retrieves documents, but then goes the additional step to synthesize an answer from those documents so that the user does not have to comb through them themselves. This is done by feeding the search results (documents) as context to an LLM which may not necessarily have trained on that information. In this way, an LLM can “learn” about a subject at inference time.
In this blog post, we describe the process of creating a RAG question-answering system to answer questions about Solr and OpenSearch based on technical documentation. We used an OpenSearch instance as the search backend and investigated an assortment of HuggingFace and OpenAI model LLMs.
Architecture
The system can be separated into 3 logical components:
- Search engine & ingestion
- Large Language Models
- UI website to interact with the system
All of these components are dockerized and are orchestrated using docker compose. The search engine is used to store documents and retrieve relevant ones during generation. The LLM component hosts a REST API which contains the heart of the RAG logic. It hits both the search engine as well as externally hosted models to produce a response. Finally, the UI website is a static front end to allow a user to interact with the system and visualize results.
Search Engine & Ingestion
We cannot just throw all of the Solr or OpenSearch documentation at an LLM and expect it to produce improved results. These excess, nonrelevant documents will just convolute the context window and for lack of a better word “confuse” the LLM. We additionally would prefer to provide the documents to the LLM in order of relevance as it helps the LLM understand which documents to prioritize. There is no better device for this than a search engine: it stores documents and allows for fast retrieval of ordered, relevant documents.
We decided to use an OpenSearch cluster for this purpose. Traditionally, search engines have used a lexical process combined with Term Frequency – Inverse Document Frequency to determine the relevance of documents. Without going into too much detail, this means that documents are split into tokens, such as words, and then for a given query, a score is calculated for each document with the following properties: the score for a document is positively correlated with how many times the query appears in it and negatively correlated with the number of times the query appears in other documents. In this way, common words such as “the”, “of”, or “there” which appear in most documents do not contribute to the score as much as rare words since a less common word is more likely relevant to the document it appears in.
While this approach works, it does not take into consideration the semantic meaning of words. The search engine actually does not know how words relate to each other or even have a concept of language. What if there was a technique that did? This is where vector search comes to the rescue. Like the name implies, in vector search, documents are embedded into vectors which have the property that the more similar two documents are, the closer their respective vectors will lie in the embedding space.
Again, the details are complicated, but some sort of neural network is generally used to approximate this function.
In order to investigate how both lexical and neural retrieval affect RAG, our demo supports both. We used the Neural Search plugin as it comes natively with OpenSearch.
To ingest documents into the engine, we used our own production grade, open-source ETL solution, Lucille. This allowed us to easily specify separate sources for both OpenSearch and Solr each with their own processing pipelines in a very simple config. Since Solr has its documentation in raw web pages and OpenSearch has it in markup, different preprocessing must be applied to both. This makes the task great for Lucille. We constructed two separate stages for the task: a HTML extraction stage which uses JSoup to extract relevant portions of a webpage and a Markup extraction stage which does the same for markup.
Large Language Models
Having a system to retrieve documents is all well and good, but there cannot be any RAG without Large Language Models. Since these models are extremely computationally expensive we used externally hosted REST APIs to run them. We chose two of the more popular platforms for this project: the HuggingFace inference and OpenAI APIs.
When RAG was first developed it was used with question-answering LLMs. These are LLMs which, given a context and question, are trained to produce an answer from the context. What’s special about them however is rather than producing an answer “from scratch” they can only return a span from the context. For example:
Context: I’m a search engineer at KMW Technology and my name is Akul Sethi. I love to go hiking and play chess.
Question: What is my name?
Answer: Akul Sethi
However, with the recent explosion in LLM development there are now LLMs specifically suited for various tasks. Our demo supports multiple LLMs to allow a user to experiment with different ways in which RAG can be used. Keep in mind that since they are all trained differently, they take prompts differently. The demo adheres to this by changing the placeholder prompt to provide an example of how the selected model receives input.
Prompting Roberta
Roberta is a model that has been trained for the task of Question-Answering as described above. It is rather small at 124M parameters but for demonstration purposes it works well. This model takes its prompt in a simple question form, such as “How do I make a collection in Solr?”.
Prompting Mistral
Mistral is a model that has been trained for the task of Text Generation. These models are trained by giving them a portion of a sentence and asking them to complete it. Because of this, if you want Mistral to tell you how to make a collection in Solr it would have to be phrased as: “A collection can be made in Solr by…”. Mistral is also a larger model than Roberta at 7.24B parameters making it second best to GPT-3 in our demo.
Prompting GPT-3
Of course no, RAG demo would be complete without the most quintessential LLM of them all: GPT-3. This is OpenAI’s proprietary LLM which is generally considered to be a conversational LLM. It is the most flexible of the 3 models in how it can take its prompts but is usually used similarly to Roberta. The big difference of course is that GPT does produce an answer “from scratch” rather than a snippet from the context meaning that it can produce “hallucinations”, or completely false answers. While GPT does produce the best answers, most likely due to its size, it is something to keep in mind (the exact size of the model is not known as it isn’t something which OpenAI has made public at the time of writing, but it is estimated to be in the hundreds of billions of parameters).
UI Website
The final component to tie it all together is the UI Website. This allows a user to query the system while controlling the various parameters.
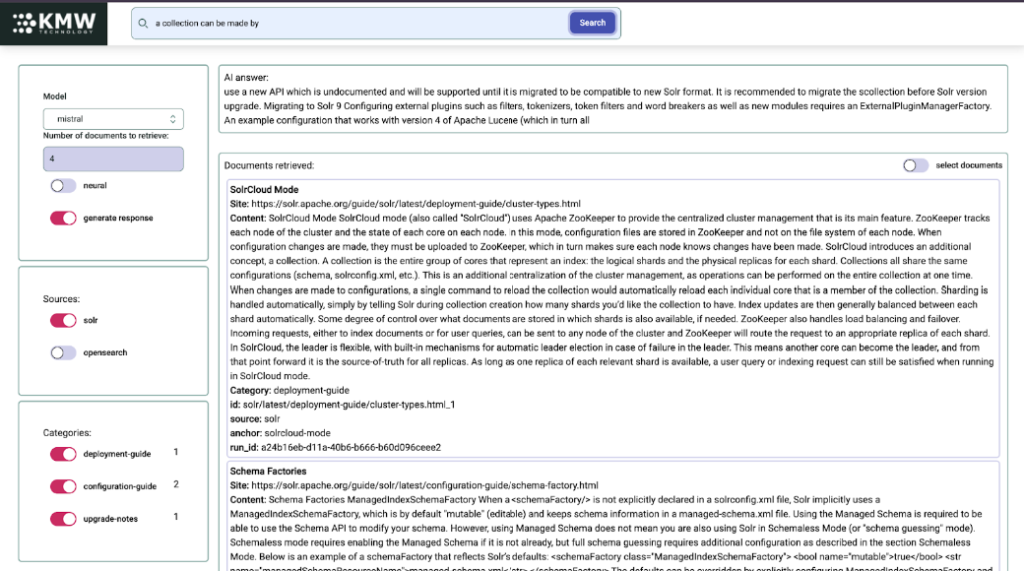
Model panel
This is for the main controls which includes the model, number of documents to retrieve, whether to use neural search, and if we want an AI response to be generated.
Source panel
As the name suggests this panel allows a user to select which document sources (Solr or OpenSearch) should be queried.
Categories panel
This panel allows a user to more efficiently sift through the documents by applying filters based on the category of the document. This is populated dynamically by the front end based on the categories of the returned documents.
Selection
The front end also supports a selection mode allowing the user to manually select which documents are used for generation. To enable, toggle the “select documents” button. Check boxes will appear next to the documents indicating if they will be used the next time the “Search” button is clicked. NOTE: when this mode is on, fresh documents will not be returned.
Key Takeaways
Retrieval
We performed a relevancy test of the results using the open source tool Quepid. This test compared RAG results using lexical vs neural search and we noticed some significant differences. Since this is primarily a question-answering system, queries will generally be formulated as questions. No surprise there. However, documentation is generally not written in that voice. For example, take the following two queries:
How do I make a collection in Solr?
How do I use facets in Solr?
In the first query we would like to retrieve documents pertaining to collections and in the second retrieve ones pertaining to facets. However, using lexical search we noticed that both queries would just return the same set of documents from the FAQ section of the documentation. Upon further analysis we realized that due to the nature of the documentation; all the words in those queries are abundant in the documents other than the word “I”. Thus, TF/IDF incorrectly assigns a lot of weight to the word “I” which is why we only see documents from the FAQ section: the only section which contains user questions.
Neural search does not succumb to this problem. It is harder to see why, since explainability does not yet exist with neural networks, but it seems as though embedding models are better able to detect the significant words in the above queries in this case.
Prompting
We found that prompting was another unexpected hurdle. The original plan was that the user question would be used as both the search query and the LLM. However, the question format which produces the best results for retrieval does not necessarily produce the best results for generation and vice versa. In fact, as each model is trained differently there is not even a format that consistently produces the best results across models.
This is definitely a point for further improvement but currently we found that optimal results can be achieved by first using the system as a search engine with a search optimized query, selecting these documents in selection mode, and then re-running with a generation optimized query.
Conclusion
Overall, we were able to show how recent developments in Large Language Models can improve how we interact with traditional search engines using RAG. Along the way, we explored various challenges which may come up while working with RAG systems and our recommendations in dealing with them.
Our final demonstration can be used both to query Solr and OpenSearch documentation, but more importantly, allows beginners in RAG to experiment with various hyperparameters and models to get a better understanding for how this cutting edge technology works.
Interested in seeing a Demo?
If you’d like to see what we’ve built in action, Contact Us!

January 10, 2026

October 4, 2025
May 20, 2025

May 30, 2024

March 29, 2023

December 17, 2022

November 17, 2022

September 30, 2022