
Search Engineer at KMW Technology
Introduction
Vector search has the potential to uncover the semantic meaning of a body of text and provide an ability to match documents from different domains. We thought an interesting use case for semantic understanding/vector search would be talent acquisition – matching a job description with a candidate’s resume and vice versa. To satisfy this use case, we created a reference implementation of an OpenSearch application able to retrieve documents based on k-Nearest Neighbors search between a job description embedding and resume embedding.
Our main goal was to create a vector search application that we can use to evaluate the technology and document what’s necessary to get it working. We wanted to uncover how vector search may or may not work with standard lexical search features like faceting, sorting and filtering. We were also interested in solving some of the operational challenges of working with a vector search application such as how to generate embeddings and how to fine-tune sentence embedding models.
Ingest Architecture
To leverage approximate kNN search in OpenSearch, sentence embeddings must be included as document fields during indexing and as a search parameter during querying. Moreover, both of these vectors must have the same dimensionality and be generated by the same fine-tuned model. These requirements motivated us to create a RESTful service to generate embeddings for both documents (at ingest time) and queries (at query time) using a sentence transformer model such as SBERT.
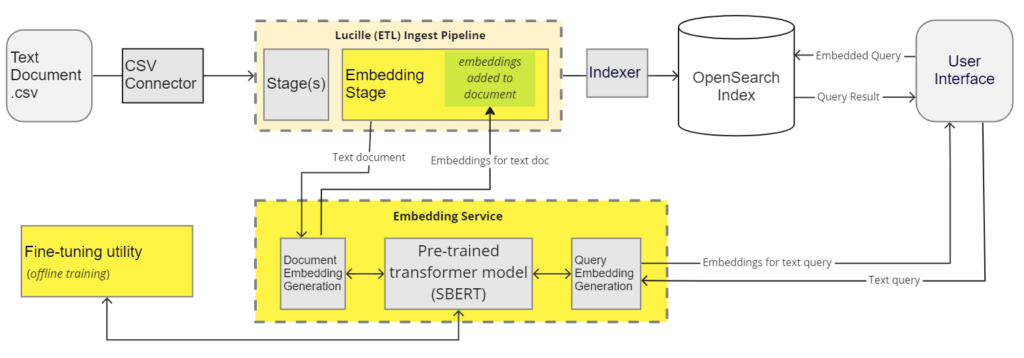
1. Embedding Service
The embedding service was created in Python using FastAPI and the Hugging Face transformer library. When the service starts, it loads the pre-trained models like SBERT from Hugging Face or from local files based on a configurable list. The service accepts text and returns embeddings at ingest time for the document and at query time for the query. A request can specify which model should be used to generate the embeddings. Otherwise, a default model is used.
2. Lucille (ETL) Stage
Documents are indexed into OpenSearch with Lucille, an open-source Java framework for ETL pipelines created by KMW Technology. An embedding stage was added to Lucille to connect to the embedding service and retrieve the embeddings for the specified fields during indexing. This stage allows specifying multiple pairs of field mappings and will retrieve the embeddings for the source fields and add them to the respective target fields.
pipelines: [
{
name: "pipeline1",
stages: [
{
class:"com.kmwllc.lucille.stage.EmbedText",
connection:"http://127.0.0.1:8000",
fieldMapping {
"resume": "resume_embedded",
}
}
]
}
]
3. OpenSearch
Before indexing the documents, we need to enable the kNN index, specify the field type for holding the embeddings as knn_vector, and set the dimensionality to the same size as the embeddings generated by the language model used by the embedding service during ingest.
{
"settings": {
"index.knn": true
},
"mappings": {
"properties": {
"resume_embedded": {
"type": "knn_vector",
"dimension": 384
}
}
}
}
OpenSearch also allows additional parameters such as specifying the nearest neighbors indexing algorithm preferred for the dataset and the type of computing resources available in the cluster, which you can view here.
Once the documents are indexed, we will be ready to make an approximate kNN query.
{
"size": 300,
"query": {
"knn": {
"resume_embedded": {
"k": 50,
"vector": [
-0.04631288722157478,
-0.03802000731229782,
...
]
}
}
}
}
Approximate KNN Search
A kNN search query traditionally uses a brute-force approach to compute similarity, which produces exact results but can be slow for large, high-dimensional datasets. Approximate kNN search methods can improve efficiency by restructuring indexes and reducing dimensionality. This approach reduces the accuracy of the results but increases search processing speeds significantly.
OpenSearch offers several different search methods that support approximate kNN. If a search method is not specified at index creation, OpenSearch will use the nmslib engine to create Hierarchical Navigable Small World (HNSW) graphs. HNSW graphs support more efficient approximate kNN search. For more information about the implementation of approximate kNN search in OpenSearch, refer to their documentation.
Traditional Search Feature Support
Computing facets/aggregations, sorting, and filtering are some of the most common search features used in lexical search. As part of our POC, we wanted to investigate how these features worked in conjunction with kNN queries.
Aggregations
As is typical in lexical search, the aggregation will be computed for the documents in the approximate kNN query result set. Here is an example query:
{
"size":10,
"aggregations": {
"category": {
"terms": {
"field": "category.keyword"
}
}
},
"query": {
"knn": {
"resume_embedded": {
"k": 10
"vector": [
0.02731507644057274,
0.010414771735668182,
...
],
}
}
}
}
Sorting
kNN query results can also be sorted according to a keyword field:
{
"size":10,
"sort": [
{
"category.keyword": {
"order": "asc"
}
}
],
"query": {
"knn": {
"resume_embedded": {
"k": 10
"vector": [
0.02731507644057274,
0.010414771735668182,
...
],
}
}
}
}
Filters
The typical filter behavior for lexical queries is to apply a filter before the query is executed, thereby narrowing the scope of documents that need to be searched. This is the default behavior for most search engines and generally known as a ‘pre-filter.’ For an OpenSearch approximate KNN query, pre-filter queries are only supported if the kNN index is constructed using the Lucene engine to build HNSW graphs.
As we previously mentioned, the default engine used to construct HNSW graphs in OpenSearch is nmslib, which only supports post-filtering of results using the post_filter parameter. This default behavior is important to keep in mind when setting up a vector index in OpenSearch, as post-filtering can impact what results are actually returned for a filter query.
When a post-filter query is executed, the kNN query will be computed first. Then the filter will be applied, potentially reducing the number of returned documents. It is essential to keep this order in mind when selecting parameters for the query. For example, we can increase the size and k parameters to ensure that the query returns a sufficiently broad set of results (i.e., to ensure that recall is high enough) before the filter is applied. In most cases, increasing k will improve the accuracy of the approximate k-NN search but will also increase the computation time.
Example kNN query using the post_filter parameter:
{
"size": 300,
"post_filter": {
"match": {
"location": "New York"
}
},
"query": {
"knn": {
"resume_embedded": {
"k": 5,
"vector": [
-0.07738623768091202,
-0.06183512881398201,
...
]
}
}
}
}
If you would like to know more about different kinds of filter queries, their use cases, and their performance in combination with kNN, take a look at this documentation from OpenSearch. One of the examples included is a Boolean filter query that allows filtering documents based on must, must_not, and should parameters. This type of query can be used to combine lexical and vector search.
{
"size": 3,
"query": {
"bool": {
"filter": {
"bool": {
"must": [
{
"match": {
"location": "New York"
}
}
]
}
},
"must": [
{
"knn": {
"resume_embedded": {
"k": 20,
"vector": [
-0.07738623768091202,
-0.06183512881398201,
...
]
}
}
}
]
}
}
}
Our examples here are based on using the approximate nearest neighbor approach because it scales well for larger datasets. The painless scripting approach is preferred if you need to use a distance function as part of your scoring method. On small datasets, the performance impact of brute force kNN may not be as consequential and can potentially provide more accurate results. In this case, one can use the custom script scoring approach with a pre-filter and brute force kNN instead of approximate kNN and post-filter.
Model Selection and Fine-Tuning
Since our queries and the corpus are about the same length, we decided to use a symmetric semantic search to have the ability to do two-way matching between resumes and job descriptions. The pre-trained model dimensionality and statistics can be found here. We started our experiments with all-MiniLM-L6-v2 and all-MiniLM-L12-v2 models with dimensions 384.
To evaluate the models, we created a small dataset with job descriptions, resumes, and the expected cosine similarity (.9 for good pairs and .1 for poor pairs). We then generated the embeddings and ran brute force kNN, recording the number of documents that appear in the result set with the expected rank. The results were evaluated with top_1 and top_k accuracy ∈[0, 1]. In the future, we would like to extend our evaluation utility to use the normalized discounted cumulative gain (NDCG) method.

To fine-tune our models, we followed the example from the SBERT documentation. The models were trained by creating (job_description, resume, score) tuples and using cosine similarity loss for n number of epochs. From our experiments, the training data’s size and quality are essential for successful tuning, and a large number of training epochs is required for the model to return top_k correct results. The table above demonstrates the improvement of the evaluation scores for models trained for 50 and 100 epochs.
Below is the documentation for the fine-tuning utility.
usage: tune.py [-h] -f FILE -o OUTPUT [-m MODEL] [-e EPOCHS] [-d DEVICE]
SentenceTransformer tuning utility
optional arguments:
-h, --help show this help message and exit
-f FILE, --file FILE path to csv file with training data
-o OUTPUT, --output OUTPUT
output directory for the trained model
-m MODEL, --model MODEL
base model name or path
-e EPOCHS, --epochs EPOCHS
number of epochs
-d DEVICE, --device DEVICE
device to use ("cuda" / "cpu"). If None, checks if a
GPU can be used.
Future Work
The next step is to evaluate the impact to relevancy of using vector search The Home Depot dataset from Kaggle is a good candidate for test data because it includes many query/result document pairs that are labeled (numerically ranked as relevant or irrelevant). By training and evaluating our application on this data set, we can further investigate whether pure vector search provides an improvement compared to lexical search.
We will also explore utilizing Quepid to visualize queries, search results, and their scores for a vector search application. Finally, we would like to create a user interface that provides traditional search options like filtering & aggregations; simplifies the queries’ embedding generation; and displays the results in a readable format.

January 10, 2026

October 4, 2025
May 20, 2025

June 23, 2024

May 30, 2024

March 29, 2023

December 17, 2022

November 17, 2022