Introduction
New in Solr/Lucene 9.x is the ability to do inequality operations to search against payloads on terms. Inequalities provide the ability to search for values that are greater than, less than, or equal to some threshold.
As search and AI continue to converge, one common use case is to be able to search for documents that have been classified by a machine learned model. These models typically output a label and confidence score for each classification. Documents can have many classifications associated with them that are generated from many different machine learned models.
The result is a data model where you have a document and a list of associated classifications. Let’s explore three different approaches to indexing and querying these documents and classifications along with a fourth approach using our recent contribution back to the Lucene and Solr Apache projects: the inequality payload query operator.
We’ll start with a data model like the following which shows a relationship between a document and the document’s associated classifications.
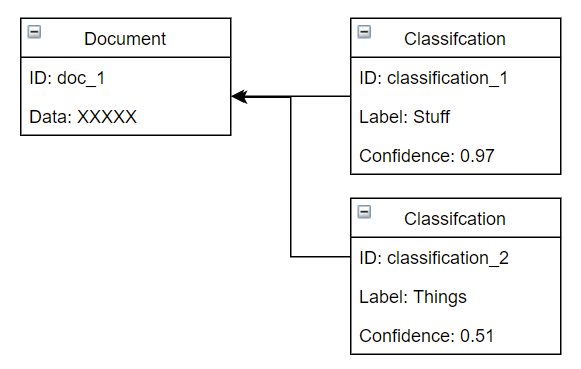
As each document is associated with zero or more classifications, each with their own label and confidence score, we are presented with the challenge to answer queries with the index to find something like the following:
“Show me all of the images that have a high confidence that they are of a person.”
For this example query, we’ll take an example index that was created by running the COCO2017 image dataset through the Yolo and the VGG16 image classification neural networks. The output classifications by either model represent the objects that were detected in the image.
The VGG16 image provides classification of 1000 object types and their confidence levels. The Yolo model provides us with 80 classes of objects that have been found with their confidence and additionally bounding box coordinates of where the image was found.
Approach 1: Do it at index time
One common approach to answer this problem is to only tag the documents as being a “person” if the classification was above a particular threshold. Having a single field on the document for the “high confidence” classifications is a perfectly valid approach. The queries remain very simple, as they are just querying for a particular label in the classification field of the document.
Example:
high_confidence:person
However, this will prevent the user from searching for documents with medium confidence labels. To address this query, the indexing of the documents could stamp two fields, one with “high confidence” labels and another with “medium confidence” labels.
Then you can search the “medium confidence” field or the “high confidence” field for the label in question. The trade off here is that at query time a search across multiple fields is required. As requirements for the confidence filter become more granular, additional bucketed fields need to be created. If the definition of those confidence levels changes the documents would need to be re-indexed to recompute the proper labels for the proper bucket. This approach works only if the definition of high confidence label is known up front and will never change.
Example:
high_confidence:person OR medium_confidence:person
In reality, users want the ultimate flexibility to decide what they consider a high confidence classification. User interfaces might even want to present this as a slider control in a search UI.
Approach 2 Do it at query time with a field for the labels
To avoid having to re-index all the documents when the definition of high confidence changes, there are a few viable options at query time to solve this problem.
One approach is to store the confidence score for each label generated by the models in separate fields on the document, one field per label.
Once the documents are indexed with a field for each label’s score, a range search can be executed on the field that corresponds to the label that is being searched. In the above example query, searching for documents that have a “person” with high confidence could be implemented as a range search on the “person” field.
For example:
person:[0.75 TO *]
This approach has its drawbacks as well in that you might have multiple persons detected in an image, each with their own confidence level. So at best, you could choose the highest confidence level of the person classification and use that for search purposes or potentially use a multi-valued field to represent each score.
An additional drawback is that each possible label requires an additional field in the index. This approach could use dynamic fields unless all of the possible labels are be known up front. Some models might classify thousands of different object types. This would result in an explosion in the number of fields in the index. Aside from the potential for the number of fields to become unruly, the UI and query language would also need to know how to map the label to the appropriate field name to properly construct that query.
Approach 3: Use joins to perform the filtering
The next possible approach is to index each classification as a child document and do parent/child join queries against Solr. There is a join query parser in Solr that allows for all sorts of database-like join queries between two queries. These queries allow for relational queries between two different datasets. As wonderful as that sounds, (and it is wonderful!) there are some limitations and drawbacks to this approach. The first and most notable is that if you have a multi-shard index, special attention needs to be paid to how the documents are routed to the shards of the index. The key constraint for the parent/child document queries is that the documents need to be routed to the shards based on the value of their join key.
In this approach a document is indexed to represent each classification that is generated for the document being classified. Every document in the index will have zero or more classification documents that relate to it. For some applications it’s ok to change how the routing is working, but depending on the query use cases, this might not be possible.
The second notable drawback to the join query approach is that it is comparatively slow and very expensive to execute as compared to other simpler term and range queries.
Lastly, the join query potentially introduces a large number of additional documents to the index. This will impact the overall search latency for any given query. Query latency is proportional to the number of documents per shard in an index. So, the introduction of all the classification documents will affect the cluster sizing, as now the index should be sized to support the additional documents. That typically means more shards and potentially servers with additional CPUs.
The basic approach is to search on classifications but return the parent document.
Search all documents that have a child document that contains a label of “foo” with a confidence greater than 0.75.
For example:
{!join to=”id” from=”parent_id” v=”+label:foo +confidence:[0.75 TO *]”}
Approach 4: New & improved inequality payload support!
Upon review, it seemed that an alternative approach to use payloads might be able to solve this problem. The payload_check query parser in Solr provides access to the SpanPayloadCheckQuery. This Lucene query provides access to the payload data while matching. Once the term has been matched, the payload is then checked to see if it’s actually a match. This functionality was used to support things like part of speech tagging for terms. It allowed developers to use a delimited payload field in the Solr schema. The values in that field could then be encoded with the term and a value delimited by a pipe.
An example of Part of Speech tagged text using the delimited payload:
Lucene|NOUN is|VERB awesome|ADJ
In addition to the payloads being strings, an integer or a floating point number can be stored there and encoded like:
Person|0.82 Cat|0.75 Monitor|0.55
The only missing piece to being able to use this for the AI model classification search was the ability to do a range search on the payload instead of just an equals operation.
We had the pleasure of recently contributing this capability back to Lucene and Solr. The patch includes the ability to provide an operation while matching now to support common operations such as greater than, less than, in addition to the equals operator. We’re happy to see that it will be included in the upcoming Solr 9.0 release.
So, now we can express the desired query as:
{!payload_check f=”classifications_dpfs” op=”gt” payloads=”0.75″ v=”Person”}
The new payload check query parser allows the user to specify the operation and the payload value to use as the reference for that operation. The above example searches the “classifications_dpfs” field for any classification of “Person” where the payload has a value greater than 0.75.
So, with this last option we can use the payload check query parser in Solr to allow us to search for labels from the classification model that are above a threshold confidence score.
The ultimate result here is that we get the full ability to search on a term with one additional dimension of metadata filtering. Term and Payload. This unlocks a lot of other possibilities when it comes to image search.
One possible example is to put the number of people found as a payload. Yolo can detect multiple objects in a scene, so the user could search for something like:
“At least 2 people and a tennis racket.”
Having the classifier output from Yolo in the following format:
Person|2 Tennis_Racket|1
A similar approach can be taken if you want to encode the center point X and Y coordinates. This would enable searches like:
“Find me a picture with a Person on the left and a Pizza on the right.”
The capabilities increase further when you start putting together scene labels along with object classification, like:
Yolo + VGG16 to get context in the search results.
By combining these two computer vision models we can start asking questions beyond what Yolo alone can answer.
“Show me a picture of at least 2 people skiing”
Yolo will detect the number of people and the VGG16 model detects the act of skiing.
Benchmarks
First, some notes about how the benchmarks were generated:
Each of the 4 approaches has the same configset. All cache sizes (except for the perSegment cache) were set to zero size. All indices in the test were a single shard with one segment and no deleted documents. All of the indices represent 1,000,000 documents. Each document has an average of 50 classifications associated with it. Each classification has a random confidence score from 0 to 1.
Approach 1 Document Example: A multi-valued field that contains only the labels that had a confidence score greater than 0.75.
{
"id":"doc_78375",
"classification_ss": ["label_7792","label_9689","label_2049","label_6581",
"label_4795","label_1780","label_6323","label_4939",
"label_8818","label_877","label_8524","label_3159",
"label_4776","label_1276","label_7104","label_4335",
"label_108","label_5675","label_424","label_7745",
"label_4144","label_2712","label_4782","label_9894",
"label_2777","label_1267","label_8919","label_5332",
"label_7159","label_4139","label_6714"]}
Approach 2 Document Example: A document with a field for each label containing the value of the confidence score for that label.
{
"id":"doc_doc_20295",
"label_264_fs":[0.5059256],
"label_4777_fs":[0.8075591],
"label_5773_fs":[0.6512147],
"label_6584_fs":[0.44860387],
"label_5053_fs":[0.77677464],
"label_2307_fs":[0.99134594],
"label_9447_fs":[0.6198554],
"label_1534_fs":[0.993752],
"label_2489_fs":[0.3812973],
"label_1578_fs":[0.67712253],
"label_7583_fs":[0.9276807],
"label_796_fs":[0.9256864],
"label_345_fs":[0.21647614],
"label_8326_fs":[0.42797613],
"label_6023_fs":[0.16159433],
"label_3220_fs":[0.82546365],
"label_4067_fs":[0.940214],
"label_932_fs":[0.71239257],
"label_7323_fs":[0.33341646],
"label_5203_fs":[0.072936356],
"label_8474_fs":[0.6330075],
"label_2032_fs":[0.45183575],
"label_6371_fs":[0.8656315],
"label_3488_fs":[0.052257597],
"label_4137_fs":[0.15416396],
"label_6509_fs":[0.52511454],
"label_8989_fs":[0.41732424],
"label_1067_fs":[0.45847535],
"label_5892_fs":[0.9040163],
"label_8169_fs":[0.26057434],
"label_3524_fs":[0.26224774],
"label_4912_fs":[0.037523687],
"label_3772_fs":[0.587384],
"label_3116_fs":[0.2450012],
"label_5069_fs":[0.70538366],
"label_5939_fs":[0.90539235],
"label_3369_fs":[0.4885615],
"label_3798_fs":[0.35722762],
"label_5111_fs":[0.3300156],
"label_1684_fs":[0.18698442],
"label_6735_fs":[0.7144106],
"label_7830_fs":[0.79478115],
"label_3240_fs":[0.7042537],
"label_2410_fs":[0.09114766],
"label_5419_fs":[0.83966637],
"label_4207_fs":[0.0035191178],
"label_4484_fs":[0.5441104],
"label_6761_fs":[0.69559073],
"label_2117_fs":[0.39736092],
"label_1298_fs":[0.8430424],
"label_5847_fs":[0.22964293],
"label_3950_fs":[0.6538746],
"label_6558_fs":[0.69730353],
"label_1273_fs":[0.024785161],
"label_3927_fs":[0.0013412237],
"label_1759_fs":[0.75639284],
"label_3553_fs":[0.5268485],
"label_5143_fs":[0.8450275],
"label_9301_fs":[0.12585384]}
Approach 3 Example Document: One document that represents the record being classified and an additional document for every classification associated with that document. The total number of documents in this index was 1,000,000 for the parent documents and 50,485,334 documents for each of the classification records.
# Example Parent Document
{
"id":"doc_729413"
}
# Example Classification Document (on average 50 of these for each parent document.)
{
"id":"doc_729413_5",
"parent_id_s":"doc_729413",
"label_s":"label_4067",
"confidence_f":0.21850449
}
Approach 4 Example Document: A document with a single field containing all classification labels with the confidence level encoded as a payload.
{
"id":"doc_doc_333114",
"class_dpfs":["label_6872|0.7949082","label_3550|0.22995031",
"label_7561|0.66999483","label_3575|0.76349306",
"label_6567|0.29170412","label_9300|0.22878802",
"label_7146|0.15249991","label_7853|0.26775044",
"label_9330|0.69193286","label_315|0.3812859",
"label_9941|0.60243666","label_5448|0.4909597",
"label_3898|0.2772404","label_3798|0.58473474",
"label_1040|0.39535648","label_3017|0.5128221",
"label_5611|0.1511501","label_7777|0.93621653",
"label_6589|0.48112237","label_6023|0.69422346",
"label_6525|0.49891192","label_6580|0.41795957",
"label_6807|0.5424252","label_6233|0.3097676",
"label_624|0.9763578","label_1726|0.3847112",
"label_9139|0.5317108","label_6330|0.64640564",
"label_2413|0.24439555","label_1372|0.17762291",
"label_562|0.3614515","label_7828|0.7642365",
"label_3786|0.19018763","label_9409|0.75261647",
"label_619|0.18773353","label_3496|0.4446562",
"label_3556|0.43172425","label_7278|0.5559282",
"label_6851|0.42342138"]}
Benchmark Results
Index Comparison
| Metric | Approach 1 | Approach 2 | Approach 3 | Approach 4 | Comments |
| DPS | 11761 | 209 | 409 | 3566 | Documents indexed on a single thread generating random data. Updates batched, no committing while feeding content. Only a single replica active. |
| Index Size | 219.32 | 906.99 | 2610 | 1220 | Size in MB |
| Memory | 1772 | 1361108 | 5556 | 1460 | As reported from solr admin gui |
| Test Query | classification_ss:label_7792 | label_7792_fs:[0.75 TO *] | {!join from=”parent_id_s” to=”id” v=”+label_s:label_7792 +confidence_f:[0.75 TO *]”} | {!payload_check op=”gt” f=”class_dpfs” payloads=”0.75″}label_7792 | Example syntax |
Indexing Benchmark Commentary
There are some interesting takeaways from this benchmark.
Indexing Performance
- As expected, with Approach 1, the documents were faster to index as some data is being discarded. Pre-filtering the data yields smaller documents, and as a result they are faster to index. It was slightly surprising to see the negative impact of having many fields on a document.
- Approach 2 documents were much larger overall compared to the rest of the approaches and as a result, this approach was the slowest to index overall.
- Approach 3 with the children documents was about 2x faster than approach 2 for indexing.
- Approach 4 with the payload was about 16 times faster Approach 2 to index. The payload approach definitely has a major indexing performance advantage over the other approaches.
Index Size
- Approach 1 yielded the smallest index as data was being thrown away and the data model is the simplest.
- Approach 2 was the most efficient in terms of index side between 2,3 and 4. This lends some of the performance issues to this approach to simply be attributed to the json formatting.
- Approach 3 using children documents had the largest index size over all, showing the impact of the additional children documents in the index.
- Approach 4 was only about 33% larger than the field based Approach 2 and less than ½ the size of Approach 3. The key item to note here is the additional .pay files in the index to store the payload data.
Memory Usage
- Approach 4 had the lowest memory overhead for having the index open. This was a very surprising result.
- Approach 2 yielded the largest surprise. The index heap usage was nearly 1000x that of the other approaches. This really highlights the overhead of having 10,000 fields in the index. This is relatively dramatic and shouldn’t be ignored.
Query Performance Comparison
| Metrix | Approach 1 | Approach 2 | Approach 3 | Approach 4 | Comments |
| Number of queries | 10000 | 10000 | 100* | 10000 | Join queries were so slow, the test was stopped after 100 queries |
| average | 1 | 2 | 1803 | 3 | In milliseconds |
| min | 1 | 1 | 1656 | 2 | ms |
| max | 6 | 22 | 2092 | 47 | ms |
| std dev | 0.55 | 0.79 | 88.28 | 1.55 | |
| throughput | 636 | 347.9 | 0.556666667 | 254 | Queries per second (single threaded execution) |
| sent kb/sec | 109 | 60.09 | 0.15 | 61.5 | |
| received kb/sec | 6124 | 8988.84 | 0.82 | 948.88 | |
| avg bytes | 9861 | 26461.3 | 1499 | 3826.1 | Average response size in bytes |
Query Benchmark Commentary
From a pure performance perspective, again, no surprise that Approach 1 is the fastest. The join query approach (Approach 3) really shows how its performance is orders of magnitude slower than simple term and range queries in Solr. The second best query performance was the field for each label (Approach 2). This really highlights how efficient Solr/Lucene is at performing range query operations. It also shows that it’s not much of a cost to use payloads compared to the expensive join operations.
One other thing to note about the payload approach (Approach 4) is that for this dataset, the json encoding of the document with the payloads is even tighter than Approach 1.
Next Steps
There are always things that can be improved and built upon. As a result of implementing this feature, it was noticed that the payload encoding and decoding code is a bit fragmented. It would be nice to centralize and consolidate some of that logic with the hope of making payloads more extensible.
There are some other novel queries that can be performed with the new payload support. For example, if using the classifications as a feature vector, a query can be created to find other documents that were classified in a similar manner to implement a “find similar” for image data.
Going beyond this, one could envision extending the payload supported data types to include a vector of floating point values to enable vector based matching calculations such as cosine, manhattan, or euclidean distance metrics for similarity.
The ultimate realization of the power of this functionality will ultimately be through NLU techniques to translate free text queries into the appropriate payload check queries. More to come on that.
Conclusion
The biggest take away here is that as you require more granular query capabilities, the expense of the query goes up. If an application truly needs to do a full relational style join query, then special attention needs to be paid to how that system is scaled. Additionally, we can also see that payloads become a very attractive design pattern due to the indexing performance, memory usage characteristics, query performance, and ultimately query granularity make it a viable approach for applications to avoid needing to scale up for using a join query.
[…] 30, 2022 Search Engine Upgrade By Kevin Watters July 2, 2022 Solr Payload Inequalities By Kevin Watters June 12, 2021 The Cross Collection Join Query By Dan Fox […]