
Search Engineer at KMW Technology
Introduction
Have you ever needed to find out more about what’s going on with your Solr deployment? The Solr Admin UI is great at communicating the overall health of the cluster, how the cores are doing and validating configuration. But sometimes you need to go a bit deeper to understand:
- What’s my query latency?
- How long are commits taking?
- Is Solr throwing any errors?
- What queries are returning zero results?
When we need to know more, we need to look at the logs.
The ability to analyze log files is foundational to monitoring the success of your Solr cloud deployment. Log files consist of events that are logged with a date, timestamp, event level (warning, error, info, etc.) and event detail. The information contained in the logs give you insight into what is happening within your system.
At KMW Technology, we focus on utilizing open-source software in our search solutions in order to support and contribute to community-driven development. As such, we have a lot of expertise in working with Solr. When it comes to analyzing Solr logs, Solr does have some out of the box tools. However, we’ve found that those tools don’t give a lot of options for creating rich visual analysis. We’ve also found there’s no great way to analyze logs in real time. So what do we do? We turn to another open-source platform: Elastic. Using Elastic’s ELK stack, we can ingest Solr log files and leverage tools like Kibana to query and visualize what’s happening in Solr.
In this post, we’ll go over how to use Elasticsearch and its tools within the ELK stack to query, analyze and visualize your Solr logs. It’s easier than you might think!
The ELK Stack
The four components of the ELK stack are: Elasticsearch, Logstash, Kibana, and Beats. The process begins with Beats, a platform with multiple different data shippers. Filebeat is one of these data shippers, and setting up Filebeat is the first step to ingesting your logs. Once Filebeat is hooked into your Solr logs, your log data can then be shipped to Logstash which will ingest the logs. When Logstash ingests and parses the log data, create an index in Elasticsearch and add the logs to this index. Once Elasticsearch has all the data, you can use Kibana to query your log data and create visualizations that aid in your analysis.

The Process
Installing & Configuring ELK
Install the following products:
Ensure that each of the downloaded products are compatible with each other, i.e. all have the version 8.4.2. You can find the compatibility matrix here.
Pointing Filebeat at Your Logs
Filebeat’s role will be to monitor the files that are in a defined input location and send them to a defined output location. In this case, the input will be the path to your Solr logs and the output will be Logstash.
You can choose to either actively monitor your logs in real time or ingest a saved set of logs that came from a certain time period. In either scenario, the Filebeat setup will be the same. However, if you are not monitoring your logs in real time Filebeat only has to run once and can be terminated when it has finished. Otherwise, Filebeat should be left running so that it can continue to send log updates in real time.
Within the downloaded Filebeat package, find filebeat.yml.
- Add the path(s) to your Solr logs under the filebeat.inputs section and set enabled to true. You can use glob to match multiple logs.
filebeat.inputs:
- type: log
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /Downloads/Logs/SolrLogs/solr.log*
- Under the Kibana section, make sure that the Kibana host is set to your specific Kibana host. You do not need to set anything for the Elasticsearch output.
setup.kibana:
# Kibana Host
host: "localhost:5601"
- Since we want to connect it to Logstash, set the output accordingly. Make sure output.elasticsearch is not set to anything and output.logstash is set:
output.logstash:
# The Logstash hosts
hosts: ["0.0.0.0:5044"]
Note: there are other sections of Filebeat that can be configured, but for this example we are leaving these sections set according to the values that are pre-loaded when you first install Filebeat.
Configuring Logstash
Logstash is an ETL tool that requires some initial configuration. It is the pipeline that takes files from Filebeat, ingests and transforms the data so that it can be indexed, and sends it to Elasticsearch to be made searchable.
Logstash has to be configured accordingly to ensure that the data that is in your logs is captured and made searchable as fits your needs. This means identifying what content from the Solr log files is important to retain and what might not be necessary. In the below example, we will walk through what we consider a basic Logstash configuration for Solr log ingestion– but be aware that your use case might be different.
Setting up the Pipeline
The first step is to set up the pipeline for Logstash. As you’ll see below, you will use Grok to match and filter the content in the logs. Grok is similar to regular expression in that it is a search pattern that can be matched to text. This will allow you to set values to fields. Some documentation and examples of Grok statements from Elasticsearch can be found here.
Within the installed Logstash package, locate the conf/logstash-sample.conf file. There should be an inputs and an outputs section.
- Add a filter section after the inputs. This will be where you can create Grok statements to filter and match the data that you want from your logs. The following code matches the time and log level from Solr logs and sets those values to the LogTime and level fields. Use the Grok debugger from Kibana to check if the Grok statements are matching the correct data.
Additionally, you can add Grok that looks like the example below, which will match the basic log configuration for Solr logs. Keep in mind you can also match error level logs and garbage collection logs.
if "INFO" in [level] {
grok {
match => [
"message", "%{DATESTAMP} %{LOGLEVEL} (%{DATA}) \[(c:%{DATA:collection}| ) (s:%{DATA}|)\] %{DATA} \[%{WORD:core_node_name_s}\] %{SPACE} webapp=\/?%{WORD:webapp} path=%{DATA:path_s} params=\{%{DATA:params}\} status=%{NUMBER:status_i} QTime=%{NUMBER:qtime_i}",
"message", "%{DATESTAMP} %{LOGLEVEL} (%{DATA}) \[(c:%{DATA:collection}| ) (s:%{DATA}|)\] %{DATA} \[%{WORD:core_node_name_s}\] %{SPACE} webapp=\/?%{WORD:webapp} path=%{DATA:path_s} params=\{%{DATA:params}\} hits=%{NUMBER:hits_i} status=%{NUMBER:status_i} QTime=%{NUMBER:qtime_i}",
"message", "%{DATESTAMP} %{LOGLEVEL} (%{DATA}) \[(c:%{DATA:collection}| ) (s:%{DATA}|)\] %{DATA} \[%{WORD:core_node_name_s}\] %{SPACE} webapp=\/?%{WORD:webapp} path=%{DATA:path_s} params=\{%{GREEDYDATA:params}\} %{NUMBER:status_i} %{NUMBER:qtime_i}"
]
tag_on_failure => []
}
if [params] {
kv {
field_split_pattern => "&|}{"
source => "params"
}
}
- Configure the output.
- Set Elasticsearch host to
"https://localhost:9200"“ - Set the template to the path. We will set up the template (mapping) after this.
- Set index name
- Set the user and password from your elasticsearch or ssl_certificate_verification
- Set Elasticsearch host to
Defining the Mappings (Index Template)
Since you’re familiar with Solr, you know that a collection schema declares the fields and corresponding data types per field. In Elasticsearch, a schema is referred to as a mapping, and the mapping is applied to a specific index. A Logstash index template is needed in order to define the mappings that Elasticsearch will use to create an index of your Solr log files.
Keep in mind that index templates are only applied at index creation or during a re-index.
If you don’t specify mappings for each of the fields that you are matching from the Grok statements, Elasticsearch will still ingest the logs and assume a type for each field. This can be problematic if Elasticsearch assumes the wrong field type. For example, if a field with an integer type is ingested as a string type you will not be able to represent it in the correct way in a Kibana graph using minimums, maximums, averages or other mathematical operations.
To start making a template, create a JSON file using the example template below. The name and path has to be whatever you set your template to in the pipeline above. There are two main components to the index template.
- Include your
index_patternsto match the indices you want. - Include the
mappingsmap. This part includes the mapping of the fields to their data type. Since you already set up your pipeline in the section above, you know what fields you are matching from the logs. For each of the fields, determine what data type they should be. For example, if you are matching query time values in your log and you called the fieldqtime_ibecause it is an integer value, you should add this to your mappings. From Elasticsearch’s documentation, here are all the different types that you can include in your mapping. Each field can only have one data type.
"qtime_i":{
"type": "integer",
"fields":{
"keyword":{
"type": "keyword",
"ignore_above": 256
}
}
}
The whole template will look something like what is below.
{
"template": "solr-logs-template",
"index_patterns": ["solr-logs*"],
"mappings" : {
"properties" : {
"@timestamp" : {
"type" : "date"
},
"@version" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"LogTime" : {
"type" : "date",
"format" : "yy-MM-dd HH:mm:ss.SSS",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"agent" : {
"properties" : {
"ephemeral_id" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"hostname" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"id" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"type" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"version" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
},
"commit" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"core_node_name_s" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"ecs" : {
"properties" : {
"version" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
},
"file" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"fl" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"hits_i" : {
"type" : "integer",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"host" : {
"properties" : {
"architecture" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"hostname" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"id" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"os" : {
"properties" : {
"build" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"family" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"kernel" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"platform" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"version" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
},
"input" : {
"properties" : {
"type" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
},
"level" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"log" : {
"properties" : {
"file" : {
"properties" : {
"path" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
},
"flags" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"offset" : {
"type" : "long"
}
}
},
"message" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"params" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"path_s" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"q" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"qt" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"qtime_i" : {
"type" : "integer",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"rows" : {
"type" : "integer",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"status_i" : {
"type" : "integer",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"tags" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"version" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"webapp_s" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"threads_stopped_for_seconds_i" : {
"type" : "float",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"wt" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
Running ELK
Now that setup has been completed, you’re ready to run all four parts: Elasticsearch, Kibana, Logstash, Filebeat.
- Run Elasticsearch. From the Elasticsearch package run
[./bin/elasticsearch]. Elasticsearch will be found at[https://localhost:9200] - Running Kibana may be useful during the configuration of Logstash for the Grok debugger. Be aware that you need to have Elasticsearch running in order to run Kibana. From the Kibana package run
[./bin/kibana]. Kibana will be found at[http://localhost:5601].This is where you will be doing the data querying and visualization. - Run Logstash to create the index. From the Logstash package run
[./bin/logstash -f logstash.conf]wherelogstash.confis the configuration file we created above. - Run Filebeat to monitor the logs and send to Logstash. From the Filebeat package run
[./filebeat -e].
Filebeat and Logstash only need to run once unless you are monitoring logs in real time.
Querying and Visualizing
Goals for Analyzing Logs
Depending on the use case, you can focus on different things when querying and visualizing logs. Some questions can be answered by querying Kibana, while in other circumstances setting up a visualization is more helpful. Since you are already interested in log analysis you probably have some specific metrics in mind, but some common analysis goals include:
- Seeing how long garbage collection takes
- Knowing how many searches have been run over a given time (per minute/hour/week)?
- Identifying the queries that take the longest time to execute
- Identifying most common queries issued to a collection
- Visualizing spikes in query traffic
- Seeing how often commits are occurring
Example Queries against Elasticsearch Index
Querying against your newly created index is simple with Kibana. Go to the menu on the top left and scroll all the way down to Management/Dev Tools. From here you can create queries in the Console and test your Grok statements in the Grok Debugger. For help understanding the specific query syntax, here is some documentation.
There are some simple queries that you can use to start off with:
To get all the indices so you can ensure the index was created:
GET _cat/indices
To get all information from one index:
GET /<index-name>/_search
{
"query": {
"match_all": {}
}
}
Finding the longest-running search:
GET /<index-name>/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"path_s.keyword": {
"value": "/select"
}
}
}
]
}
},
"aggs": {
"doc_with_max_qTime": {
"top_hits": {
"sort": [
{
"qtime_i": {
"order": "desc"
}
}
],
"size": 1
}
}
},
"size": 0
}
Finding the most common query:
GET /<index-name>/_search
{
"aggs": {
"frequent_query": {
"terms": {
"field": "q.keyword"
}
}
},
"size": 0
}
Finding percentiles (aggregating on query time):
GET /<index-name>/_search
{
"aggs": {
"qTime_percentiles": {
"percentiles": {
"field": "qtime_i",
"percents": [
90,
95,
99
]
}
}
},
"size": 0
}
Example Visualizations with Kibana
Once you understand the data that you are looking at, you can create a dashboard with visualizations. Create a visualization by navigating to Analytics -> Discover or Analytics -> Dashboard if you already know what you’d like to make up a dashboard.
The ability to create visualizations with Kibana is one of our favorite reasons to look at Solr logs using Elastic stack. It is easy to create dashboards that convey a lot of information in an easily digestible manner. While it is possible to use grep commands in a console to see commits per collection, you can see in this example that a visualization is a lot easier to understand than the results you would get from grep.
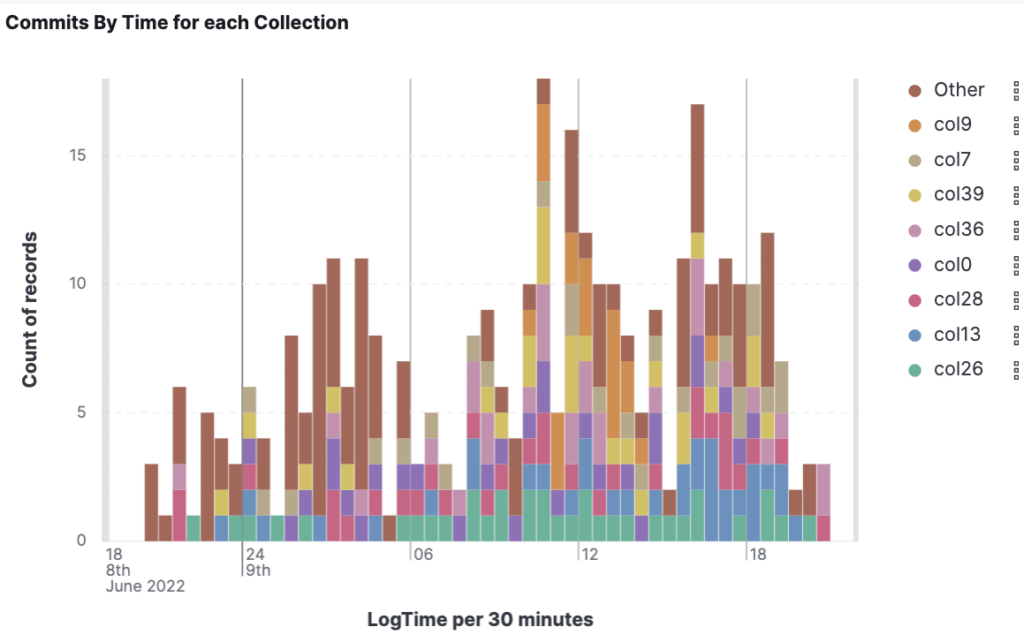
Conclusion
While there is a bit of up-front work required with this approach, the payoff is having a great way to look at your Solr logs both in real time or as needed. Let us know what type of questions you hope to answer when looking at your Solr logs, and if you have other approaches that you prefer.
If you’re experiencing issues with your Solr (or Elasticsearch, or Opensearch) cluster or need help interpreting your logs, please contact us!

January 10, 2026

October 4, 2025
May 20, 2025

June 23, 2024

May 30, 2024

March 29, 2023

November 17, 2022

September 30, 2022